Rust, WebAssembly, and FCKed Editor, a cursed markdown editor
I've made another intentionally useless website! It only took me an entire year. 😄
Really, though, looking at some of the dates on these files, I started working on this project early this year, and abandoned the Flutter version around July. I'm sad that I couldn't get it to work, but Rust/Dart interop just wasn't working for me.
The Flutter version of FCKed Editor, which only works in debug mode:

So I shelved the project for a while, and it existed as just a Rust binary that worked on the command line. But I wasn't satisfied with putting all the work into the markdown parser to never finish the editor part of the project. I then decided to compile the Rust code to WebAssembly and use it as part of a browser-based editor.
I did intend to make intentionally useless websites after all, not intentionally useless desktop applications. (I will one day complete a Flutter app, though. Mark my words.)
The result is FCKed Editor, a browser-based markdown editor that will take your normal markdown and transform it into all kinds of different unicode characters and emojis.
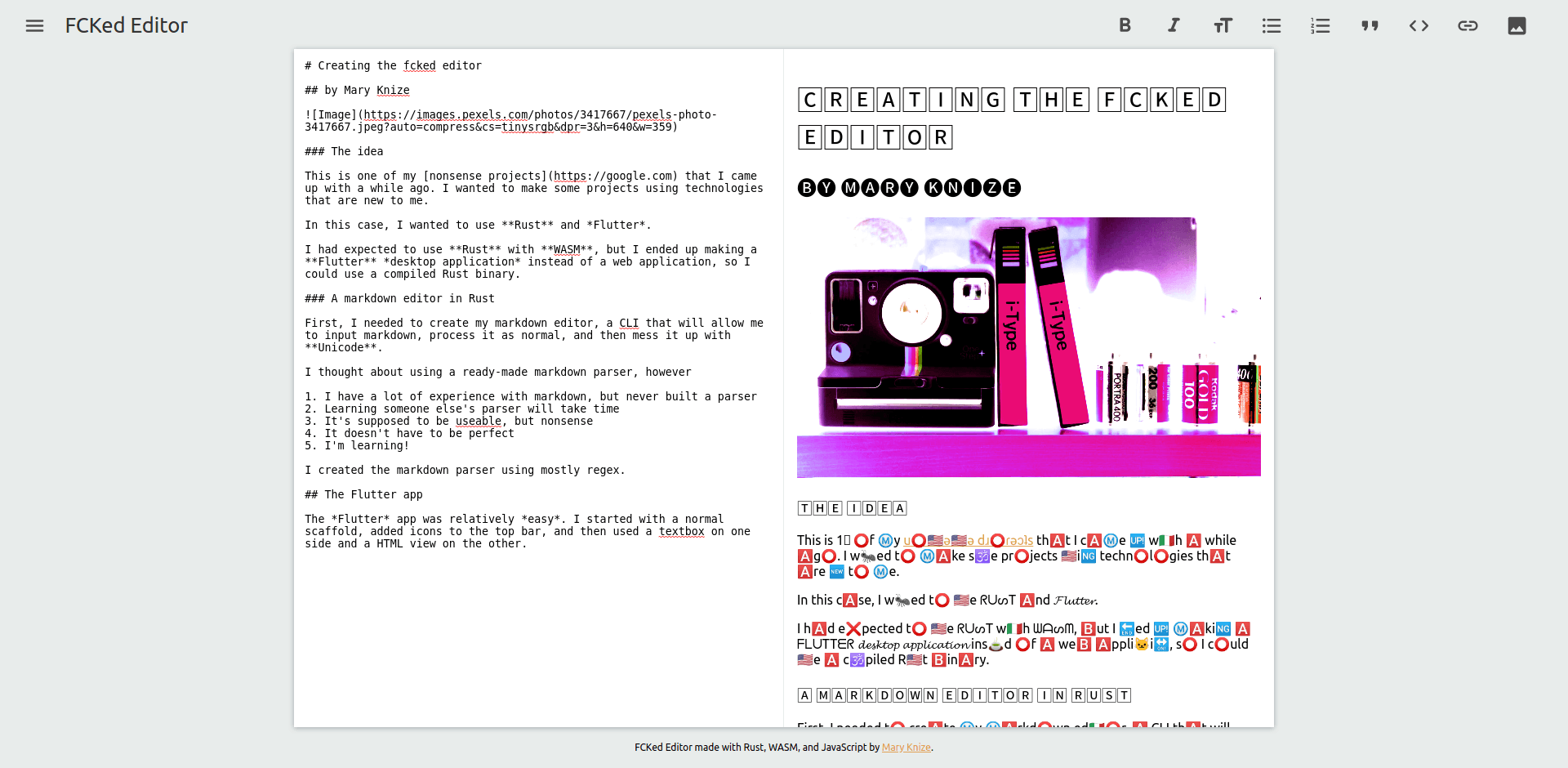
And yes, the name is a play on the old FCKeditor, and I assume that name was changed to CKEditor because, well, I know how I read "FCKeditor". So I decided to make an editor that really FCKs your text. 😉
You can check out the Github repository for all the code while I share some highlights below.
Index
- Creating the Rust markdown parser
- Compiling WebAssembly
- The JavaScript editor
- Bugs and optimizations
Creating the Rust markdown parser
You can find the Rust files under /src/rust/ in the repo. As you can see in the Cargo.toml file in the root of the repo, I have two compile targets, the WebAssembly library, from lib.rs, and a binary file from main.rs. Both files import the main file, processing.rs. The difference is, main.rs parses the command line arguments and uses the provided markdown string to generate HTML, whereas lib.rs exposes a WASM function called process that accepts a string to generate the HTML.
All of the markdown to HTML conversion is done in processing.rs. You'll see that in the prelude of this file that I'm importing two other modules that I've created, font_fckin and emojifck, which deal with unicode fonts and emojis, respectively.
You'll see in the process_text function that we run different processing functions in order, starting with block-level HTML elements like headers and blockquotes, and followed by inline elements like bold and italic text, and finishing by processing paragraphs.
Each processing function uses regex to search for the required markup, then captures the text that needs to be transformed and surrounded by HTML tags. As you can see, the text is sent to the modules that do the text transformations within each of these functions.
For example, in process_bold_italic:
let split_line = line_dup.split(&cap[0]).collect::<Vec<&str>>();
match cap[1].len() {
1 => line_dup = split_line[0].to_owned() + "<i>" + &italic_fck(cap[2].to_string()) + "</i>" + split_line[1],
2 => line_dup = split_line[0].to_owned() + "<b>" + &bold_fck(cap[2].to_string()) + "</b>" + split_line[1],
_ => line_dup = split_line[0].to_owned() + split_line[1],
}The line is being split because this is an inline element, so we want to add the other text around these italic and bold elements. In the case of one asterisk element, we want to surround the text with <i> tags, and in case of two, surround the text with <b> tags. If there's no match, just return the line unchanged. (Looking at this now, I don't need to actually concatenate the split lines, just return the original line. Refactoring!)
You'll notice in between those HTML tags I'm calling functions italic_fck and bold_fck. Those are both located in processing/font_fckin.rs, which we'll look at now.
The font_fckin.rs file begins with multiple static arrays of 62 characters each. The first array is standard ASCII text. The other arrays contain various variations of each character. There's a main function in this file, called fck, that takes the text and the desired transformation alphabet as arguments. For each character in the text, it will look up the position of the character in the ASCII array, then return the corresponding character in the transformation array.
But what about the emojis? In regular paragraph text, some of the text is transformed, fully or partially, into emojis.
This is where the other two files, emojifck.rs and emojis.json come into play. Now, emojis.json, I don't remember where I found it, but I think it was somebody's Github gist (I'm sorry, it was a year ago). It nicely lists out 4032 emojis with descriptions, shortnames, etc. Now that I've been using the markdown editor for a while I've noticed that some emojis are used frequently, and some never at all, so pruning this list down would speed things up much faster, I'm sure.
At the beginning of emojifck.rs, I defined a struct to take all of the fields from the json files and make them something the Rust code can use. Then, serde_json imports the json file and creates a vector that contains each Emoji struct. Then, it finds matching keywords between the emoji and the text, and replaces those substrings with the emojis.
This is by far the least efficient part of the markdown parser, and I'd like to optimize it in the future.
Compiling WebAssembly
As I mentioned above, lib.rs is where the wasm_bindgen code lives that allows me to expose the main process_markdown function to JavaScript.
The contents of lib.rs, which exposes the Rust function to WebAssembly:
mod processing;
use wasm_bindgen::prelude::*;
use processing::process_markdown;
#[wasm_bindgen]
extern {
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[wasm_bindgen]
pub fn process(markdown: &str) -> String {
process_markdown(markdown.to_owned())
}I used the instructions in the Compiling from Rust to WebAssembly guide to learn how to transform my Rust code into usable WebAssembly. Basically, I've installed wasm-pack using cargo install wasm-pack and added the wasm-bindgen create to my Cargo.toml. I've also added information to my Cargo file to generate the WASM library:
[lib]
name = "markdown_fckr_wasm"
path = "src/rust/lib.rs"
crate-type = ["cdylib"]Once that was all finished, I could build the package with wasm-pack build --target web and my WebAssembly code appears in a /pkg directory at the root of my project. After that, all I had to do was import the init and process functions from /pkg to use them in my JavaScript.
The JavaScript editor
All of the javascript files are in /src/html/js, with one HTML file and an SCSS file.
I had tried using my WebAssembly code with both React and Vue, however, the setup process for both felt needlessly complicated. In comparison, the setup for regular HTML/JavaScript was relatively easy:
import init, {process} from "../pkg";
init().then(() => {
if (editor.value) {
this.preview.innerHTML = process(editor.value);
}
});There's a bit of other code in there for processing updated text (and this could be refactored), but that's all I really needed to import my WebAssembly code and use it!
You'll see that the rest of my JavaScript code is just class-based and component-focused. It could be refactored a bit, I'm sure, but I kind of quick 'n dirtied it over a Saturday afternoon.
Bugs and optimizations
Since I'm still learning Rust and I finished the client-side code very quickly, there are a number of bugs that I've identified, and some optimizations that I could make. When I have some time I might knock a few of these out, but I'm excited to get on to my next project!
Todos:
- Pare down the emoji list for optimization.
- Re-work the emoji indentification function to identify more matching emojis.
- Fix some redundant code.
- Make a dark mode for the editor.
- Accessibility! Modals especially don't have focus traps, among other issues.
- Fix an issue where opening a markdown file, clearing, then opening the same file doesn't work.
- Adding images and links can delete some existing text.
- Undo/redo